Alexander Ezharjan
Introduction
Introduction
This reference book is mainly to discuss the detailed knowledge of basic computer graphics based on the soft renderer project called Render Engine, which is a tiny graphical rendering engine developed via pure C++ without any third-party-libraries included.
The content of this book is separated into many parts so that we are able to to have a deeper view into each section.
The first section is this Introduction it self.
The second section is to discuss the mathematical basis for computer graphics. The advanced part as well as those part that have tight relation with the physics is not included, as we are just learning the basic knowledge of computer graphics, not the advanced ones.
The third section is to discuss the inside of render pipeline, which is a significant aspect in the study of computer graphics.
The forth section is to discuss the basic unit used in render engine — Vertex. A vertex stores lots of information including position, tex-coord, normal etc,.
In order to relate the CG knowledge into the application, we have to apply the theory into reality by programing, With this notes, however, the co-related project demands the basics for C++ programming. But if you take a look at the project code, you will notice that the application of the programming language is really in basic way, as too many properties of C++ is not utilized at all. Only some of the basic data structures and methods of the STL is used to make the code more accessible as well as to facilitate the project. Note that any other programing languages are OK to apply the theory I clarified in this book.
Math Basis
Math is needed as the basic tool for every field of science. As the base of the computer science, I myself also regard it as the base of computer graphics, for many algorithms can not escape from the use of math. I separated it as a single chapter so as to mention its importance as well as to show you the utility of math in computer graphics.
In math, we have vectors, matrices, coordinates and more. These are all used in computer graphics. If you have ever used OpenGL or any other libraries, you’ll notice that the math is actually provided as basic APIs and using them is quite simple. But if you are writing the CPU based renderer like I have done in this project, you ought to know the inner activities that these APIs are conducting. Here I am going to show you some of the APIs that I wrote:
1 | float RadToDegree(const float& rad) { |
Actually, some of the APIs can be directly gain from STL or ‘math.h’ while you’re using C++, such as the function ‘RadToDegree’ above can also be found in Lua’s inner math library, but writing them done is a way to apply what you have learnt into practice. Hope you can directly use the ones that the inner libraries provide rather than writing them by yourself so as to avoid mistakes and prevent the performance of your application from being lowered.
Here are some of the APIs when defining Vectors:
1 |
|
Rendering pipeline
Learning the rendering pipeline is crucial for the study of computer graphics.
Here are three major stages in the rendering pipeline:
Application StageGeometry Conduction StageRasterization Stage
1. Application Stage
In this stage, all of the elements you got is in its original state. For example, if you’re going to read the positions of an OBJ formatted model in to the computer buffer so as to construct each of the position into a vertex and then calculate them later, you should have a formatted OBJ model first and then read those positions into a vector orderly. Whatever your model’s format is, FBX, MTL or any other formats, reading into the position information to a vector is the first step.
Besides the positions information, there are still lots of information such as the texture coordinates, the normal vector, the blend weights and blend shapes, the bone weights to read from a file(OBJ, FBX, MTL, etc,.) that holds the models information. These information builds up the attributes of a vertex. Just take the texture coordinate (in the project it is name “Texcoord”) for example. The texture coordinate, as a basic attribute of a vertex, it includes the information about a vertex’s U axis and V axis, which informs us the way to put texture on the model.
Finally, as these information(the texture coordinates, the normal vector, the blend weights and blend shapes, the bone weights) are stored in a vertex orderly and correctly, a simple but formal vertex is born. Its structure should be like the structure shown below:
1 | struct SimpleVertex |
You might see that the Vertex struct is simple compared with the ones you might ever seen in other materials, as I have excluded many of the attributes for this vertex struct like the blend weight, the blend shapes and the bone weights that I have described in the paragraph above. Also, the attributes like “rhw”, which represents the reciprocal of homogenous W, is not shown directly in this chapter just for the convenience of clarifying the process of the Application Stage, but they will later be added in.
Let’s take a closer look at the inside of this simple vertex.
You may realize that the position attribute in our vertex is a four-dimensional vector rather than a 3D one. So what does the fourth dimension represents for? Why we use a four-dimensional vector to store a position in a three-dimensional scene? Actually the W, which is the forth dimension, represents for the homogeneous coordinate. Now tha question lingers that why we use homogeneous coordinate while 3D coordinate is enough?
The answer of the questions above lays on the three factors below:
(1) It plays an important role when conducting homogeneous transformation. The Homogeneous Transformation Matrix For 3D Bodies is shown below. You will notice that it will be easier for multiple matrices’ multiplication if you use have N+1 dimensions than directly calculating N dimensional matrices. Especially the rotation will be more convenient for the quaternion itself demands 4 dimensional vector.
![]()
(2) In real world, two parallel lines will never meet with one another mathematically, but in perspective(human-eye) projection it will. In Euclidean space(geometry), two parallel line on the same plane cannot interest, or cannot cannot meet each other forever. Euclidean space describe our 2D or 3D space so well, but they are not sufficient to handle the projective space. What if this point goes far away to infinity? The point at infinity would be (∞, ∞) and it becomes meaningless in Euclidean space. The parallel lines should meet at infinity in projective space, but cannot do in Euclidean space. Mathematicians have discovered a way to solve this issue: Homogeneous Coordinate. Adding the W as the forth dimension can transform a vertex from Euclidean space to projective space while dividing to W can transform it back.
For example:
- A = (x1, y1, z1)
- B = (x2, y2, z2)
- A // B
1 | αx1 + βy1 + θz1 + d = 0 |
1 | αx2 + βy2 + θz2 + d = 0 |
In perspective projection, even though these two lines are parallel, they still intersect in some point. But how to get that intersected point? Just add the homogeneous coordinate like I did below:
1 | (αx1/w)*w + (βy1/w)*w + (θz1/w)*w + dw = 0 |
1 | (αx2/w)*w + (βy2/w)*w + (θz2/w)*w + dw = 0 |
Then we will find out a point that intersects the two parallel lines in projective space.
(3) It’s easy to find out a vector from a point. The point, or the position is described as (x, y, z, 1) while a vector is described as (x, y, z, 0).
(4) It will be easier to describe the intersection points of lines with lines and planes with planes.
Here is the structure of a four-dimensional vector. You’ll notice that the struct Vector4 actually has 4 dimensions: X, Y, Z and W, and all of them are defined in ‘float’ type rather than double or integer. Because either using an ‘integer’ type or a ‘double’ type is inappropriate in this circumstance. Using an ‘integer’ may lose the detail of a position while using a ‘double’ type may be space-consuming.
Now here is a significant question that why we choose to use 4 dimensional vector to describe a position in 3 dimensional space while the 3 dimensional vector is enough? What is the forth dimension ‘w’ actually? Answer to these questions have actually been answered above.
1 | struct Vector4 |
In order to make the four-dimensional vector available and convenient to use in a real project, we have to make some APIs for it. The class below shows a more mature structure of a four-dimensional vector, including initialization constructor, copy constructor, overridden operators, and ‘get()s’ and ‘set()s’ for needed private members.
1 | class Vector4 |
Among initialization constructor, copy constructor, overridden operators, the overridden of the vector is closely related to the mathematics. No need to mention that the operators ‘plus’ and ‘minus’ are easy to understand, but the overridden operators of ‘*' and ‘^' are a little bit hard to understand. I use the overridden operator for ‘*' to represent the inner product of two vectors, while using ‘^' to represent the cross product(namely: outer product) of the two vectors.
We need to know the differences between the inner product and the cross product.
The inner product of the 2 vectors is just to make the two vector multiply in mathematical way, the detail of the inner product of 2 vectors is shown below.
An inner product is a generalization of the dot product. In a vector space, it is a way to multiply vectors together, with the result of this multiplication being a scalar. A simple inner product of the two vectors is shown below
1 | A*B = ||A||*||B||*cos(θ) |
The cross product of the 2 vectors is totally different for just multiplying the vectors and it has distinct meaning from the inner product. The detail of the cross product of 2 vectors is shown below.
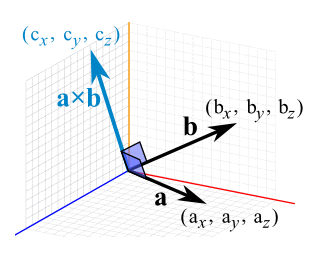
The Cross Product a × b of two vectors is another vector that is at right angles to both:
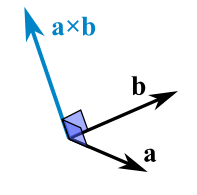
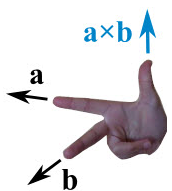
The cross product could point in the completely opposite direction and still be at right angles to the two other vectors, so we have the: Right Hand Rule.
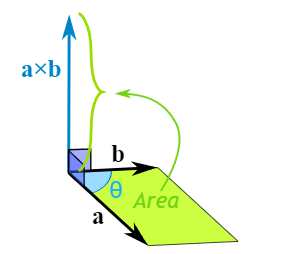
The magnitude (length) of the cross product equals the area of a parallelogram with vectors a and b for sides:
See how it changes for different angles:
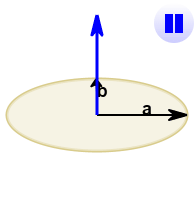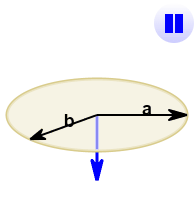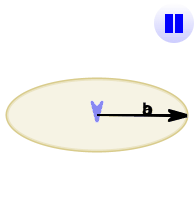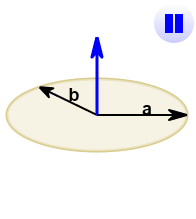
The cross product (blue) is:
- zero in length when vectors a and b point in the same, or opposite, direction
- reaches maximum length when vectors a and b are at right angles
And it can point one way or the other!
So how do we calculate it?
We can calculate the Cross Product this way:
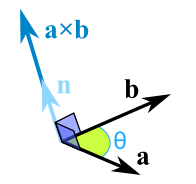
1 | a × b = |a|*|b|*sin(θ)*n |
- |a| is the magnitude (length) of vector a
- |b| is the magnitude (length) of vector b
- θ is the angle between a and b
- n is the unit vector at right angles to both a and b
OR we can calculate it this way:
When a and b start at the origin point (0,0,0), the Cross Product will end at:
- cx = aybz − azby
- cy = azbx − axbz
- cz = axby − aybx
Next, there is a color attribute in our vertex called ‘SimpleVertex’. The color attribute is defined as a Colour type, which is also a self-defined type like ‘Vector4’. The color attribute stores a position’s color information, so that we can achieve lighting based on it. The inside of the ‘Colour’ type can also be regarded as a C++ struct, its structure is shown as below:
1 | struct Colour |
Its outlined structure is so simple that only contains three float members to represent three primary colors of the light, including a number to represent the alpha.
Also, in order to use it in the real project more conveniently, basic APIs should be added into the ‘Colour’ structure above, as well as some more color-related APIs. The final structure of the color will be like the one below:
1 | struct Colour |
One important thing to mention in the code above is the comparison of the two float-typed numbers. In computer, a float-type number may well not be the exact number we saw on log, it may hide subtle bias behind its decimal point, especially those float-type numbers after having mathematical operations. Remember that 1.0 - 1.0 in computer may not be 0 at all. To avoid this, we have to use subtraction and epsilon when comparing 2 float-type(or double-type) numbers. For example, if you want to know whether two float-type numbers are equal, subtraction of these two numbers is the first step, then just compare the subtracted result with the epsilon---a pretty tiny number that we have previously defined before. If the result is smaller than the epsilon, it means that the two float-type numbers are equal, vice versa.
Besides the basic APIs and operators we have mentioned above when talking about the ‘Vector4’, here we can see a different API called ‘ClampColor(Colour& color)’. As the word’s own meaning goes, the Clamp is a way to clamp some number in or der to make it into the range previously set, let’s just call that range ‘valid range’. So it is a simple conduction just to avoid the number being outside the bounds of range. For example, if you only want to ensure the digits you get are within the range of x and y, mathematically written as [x, y], you can just take y — which is the roof of the range — if some number is bigger than y, vice versa. The code below shows how does the clamping works:
1 | float Clamp(const float& param, const float& min, const float& max) |
An optimization is just shown below:
1 | float Clamp(const float& param, const float& min, const float& max) |
But why we clamp colors?
As a common sense that we can use 01 or 0255 to represent a color’s attribute(R, G, B, A). In this case, we use 0~1. So this demands each of the color lies within the range of [0, 1]. In calculating float-type-based colors, because of the complex algorithm we use, it is almost possible that we gain a number outside the range we want. So clamping is always necessary.
The third member in our vertex is ‘Texcoord’, which represents texture coordinate, and its structure is very simple that only has two float-typed member, one is ‘U’ and the other is ‘V’. Just see the struct below:
1 | struct Texcoord |
Texture coordinates, also called UVs, are pairs of numbers stored in the vertices of a mesh.
These numbers are often used to stretch a 2D texture onto a 3D mesh, but they can be used for other things like coloring the mesh, controlling the flow across the surface , etc.
Game engines commonly use two texture coordinates, U and V, for mapping the width and height of a texture. A third axis W can also be used for depth if you are using a 3D volume texture, but usually this coordinate is removed for efficiency.
Texture coordinates are measured in a scale of 0.0 to 1.0, with 0.0 and 1.0 at opposite sides of the texture. When a model has a UV distance greater than 1 (for example, UV goes from -1 to 2) then the texture will tile across the model.
These numbers are usually hidden from the artist, replaced by helpful visual representations of how the textures are projected. Planes, cylinders and spheres help the artist align the textures in a visual way, but it helps to know that games only see the UV numbers that these shapes create.
Texture coordinates define how an image (or portion of an image) gets mapped to a geometry. A texture coordinate is associated with each vertex on the geometry, and it indicates what point within the texture image should be mapped to that vertex.
Each texture coordinate is, at a minimum, a (u,v) pair, which is the horizontal and vertical location in texture space, respectively. The values are typically in the range of [0,1]. The (0,0) origin is at the lower left of the texture.
For (u,v) values outside the range of [0,1], the Texture Wrap Style property describes how this is handled.
Texture coordinates may also have optional values “w” and “q”. This is often represented as (u,v,w,q). These coordinates are both optional, so you may have, for example, (u,v,w) or (u,v,q).
The ‘w’ is used for more complex texture mapping in 3D space and is seen relatively infrequently in most workflows. This mapping in 3D may be in relation to 3D textures or 2D texture variations in 3D such as shadows. It can also be used with 2D textures that are intended to represent complex irregular surfaces in 3D.
The ‘w’ is used when rendering, in conjunction with the texture’s transformation values such as rotation, shearing, scaling, and offset. w is an extra value against which to multiply the texture transformation values, and may be used when you want to take perspective into account (such as in shadow mapping). It works the same as when you transform a location in object-space to 3D (solid) screen-space via a world-view-projection matrix. By multiplying the uvw with projection transformation values, you end up with two coordinates (often called s and t) which are then mapped onto a 2D texture.
The ‘q’ is used to scale texture coordinates when employing techniques such as projective interpolation. For most use cases, if a system can only handle (u,v) texture coordinates and is instead offered (u,v,q) values, a location of (u/q,v/q) may be used.
As we have took so much time on introducing the basic elements called ‘vertex’, we are sure that we have appropriate data structures to store the basic information of a 3D model. Let’s go on to the next step: Reading the model into the memory, which means that we are going to use our vertex-typed container to store each of the vertex from a 3D model. In C++, its convenient that we can use ‘vector’ in STL as a list to store all of the information we read from the model. Using ‘vector<SimpleVertex>‘ to represent a list of ‘SimpleVertex’ that we have just constructed above. Then comes the reading of a 3D model file. In this case we use OBJ format as it’s file structure is easier understand and visible in file format rather than a binary format like other model files. Lets take a simple look at the content of an file with OBJ format:
1 | # File Created: 25.02.2021 17:35:16 |
The content of the OBJ file above is a pretty simple once, with many details ignored but the whole structure is entirely considered. The ‘#’ can be regarded as comments, there is no headers or tails in any OBJ files. Beginning with the vertex data, the ‘v’ represents the geometric vertices, ‘vt’ means ‘texture vertices’, ‘vn’ is ‘vertex normals’, and in some of the OBJ files there is ‘vp’, which means the parameter space vertices. Then comes the groups, ‘o’ is for the name of the object, ‘g’ is for the name of the group. The ‘f’ is crucial for it means ‘face’, the vertex indexes are split by ‘/‘, and always remember that the structure is mainly controlled by geometric vertices and the faces. We just stop deepening into the content of the file format as the detailed introduction about the OBJ file can be found online if you’re interested. Besides, you can even use FBX in your project rather than this kind of simple OBJ files.
Next, just I’m gonna show you the way to read OBJ file into our vertex container, namely, the computer memory we have constructed before. You can see that I divides the OBJ model data into the types(‘v’, ‘vt’, ‘vn’, ‘f’) before reading into the container just in accordance with the content of the files mentioned above.
1 |
|
By now, we have prepared a model data well. As you can see that the application stage is conducted in CPU, the programmer has the full control on every step and operation happened in this stage. You can try to reduce the count of the triangle during this stage in order to render it fast in the next stage, but the cost is obvious that the detail may lose. The CPU will send the data(model data which combined with vertices, vertices which includes positions, normals and texture coordinates) we stored into the hardware for the stage.
2. Geometry Stage
The model data prepared and sent from the application stage will be used as the input content for geometry stage. The main tasks of the geometry stage is to tranfer the vertices, do the clippings, shad lights, make projections and conduct screen mappings.
First and foremost, in order to make the mathematical calculations more unified, I have to mention that I use radiant(0~Π→0~180°) while describing an Euler angle, and use 0~1 rather than 0~255 while describing a color value, and use ‘vector • matrix’(vector-on-the-right-side) rule. The matrix are in ‘row-first’ order. Left-hand coordinate is used while doing geometric transforms.
In this stage there is a very important process called ‘MVP Transformation’, which is actually the combination of the ‘Model Transform’(the process during which we transform the model into its own space to the world space), ‘View Transform’(the process during which we transform the model from the world space into the view space) and the ‘Projection Transform’(the process during which we make the projection to the models in view space and transform it into the projection space). Let’s take a look at the detailed process of the geometry stage step by step.
Firstly, we have to transfer the model from its own space into the world space, but what is a ‘world space’? The world space is actually a space that holds all of the models, formally: objects. It should be able to hold all the objects with universal rules. The rule is originated from the world coordinates, which means that the world coordinate itself is a universal rule to all of the objects that are being rendered in the world space. Once we have learnt the origin of the universal rules, we are able to describe it in math, and you will find that describing a coordinate is simple in mathematics. It is a common sense that the coordinates can be easily described via matrix. As we can use a unit vector to form the base of a vector space, every vector in the space can be expressed as the linear combination of unit vectors, we can use a unit matrix to form the base of a matrix space. This means that the world space coordinate should be a unit matrix, so as to hold all the other objects. Thus the world space is created. Generally, we regard a unit matrix as a world space matrix, a world space, a world coordinate. A unit matrix is shown below, which can represent the world matrix. We can use a 3x3 matrix to represent a 3D space, but we choose 4x4 matrix, why? Because the position of our vertex is constructed in 4 dimension, with ‘w’ which represents the homogeneous coordinate. And we know that the mathematical rule does not allow us make arithmetic operations between a 3x3 matrix and a vector4. Also, the homogeneous coordinate W is crucial in the next steps that we can not lose it, we have to store it so as to use it later. As we use 2 dimentional array to define a matrix, we have to be clear about the inner side of it. In computing, row-major order and column-major order are methods for storing multidimensional arrays in linear storage such as random access memory. The difference between the orders lies in which elements of an array are contiguous in memory. In row-major order, the consecutive elements of a row reside next to each other, whereas the same holds true for consecutive elements of a column in column-major order. While the terms allude to the rows and columns of a two-dimensional array, i.e. a matrix, the orders can be generalized to arrays of any dimension by noting that the terms row-major and column-major are equivalent to lexicographic and co-lexicographic orders, respectively. Data layout is critical for correctly passing arrays between programs written in different programming languages. It is also important for performance when traversing an array because modern CPUs process sequential data more efficiently than non-sequential data. This is primarily due to CPU caching which exploits spatial locality of reference. In addition, contiguous access makes it possible to use SIMD instructions that operate on vectors of data. In some media such as tape or NAND flash memory, accessing sequentially is orders of magnitude faster than non-sequential access. We cannot clearly see whether the world matrix shown below is in row-major order or in column-major order for it is a unit matrix and the transpose of a unit matrix is actually itself, but I have to mention that all the matrices defined in this book and used in the relevant final project is in row-major order.
1 | WorldMatrix = { |
Then we have to place our models into the world space. As we have stored the model in a vertex which contains the attribute of position in 4 dimentional vector type, we can just multiply each of the position vectors with the world space matrix, thus transforming the positions of the model from its own space into the world space.
1 | (type:matrix4f)ModelInWorldSpace = (type:vector4)ModelVertices[n].position * (type:matrix4f)WorldMatrix |
Notice that all of the interactions on the object/models come from user side is applied on the models/objects in world space. This means that the rotation transform, scale transform and translation transform are conducted directly after we placed the models/objects in the world space through world matrix. First we have to map the user interaction from screen to 3D space if needed, for example, it’s needed that we map the rotation angle from 2D screen into 3D virtual world space if we want the user interact directly through the 2D screen when changing the rotation of the models/objects. Just multiplying the world matrix with the transform matrices will make the objects/models transform in the way we want. But how to describe our transform for the objects/models? Here are the details of the rotation matrix, scale matrix and transformation matrix that we should bear in mind:
Rotate by X-axis
1 | RotationXMatrix = { |
Rotate by Y-axis
1 | RotationYMatrix = { |
Rotate by Z-axis
1 | RotationZMatrix = { |
The way to build out these matrices in C++ goes like the codes below:
1 | Matrix4f Matrix4f::getRotateXMatrix(const float& thetaX) |
But notice that the direct rotation via Euler angles on any objects/models will cause Gimbal Lock. Gimbal lock is the loss of one degree of freedom in a three-dimensional, three-gimbal mechanism that occurs when the axes of two of the three gimbals are driven into a parallel configuration, “locking” the system into rotation in a degenerate two-dimensional space.
The word lock is misleading: no gimbal is restrained. All three gimbals can still rotate freely about their respective axes of suspension. Nevertheless, because of the parallel orientation of two of the gimbals’ axes there is no gimbal available to accommodate rotation about one axis.
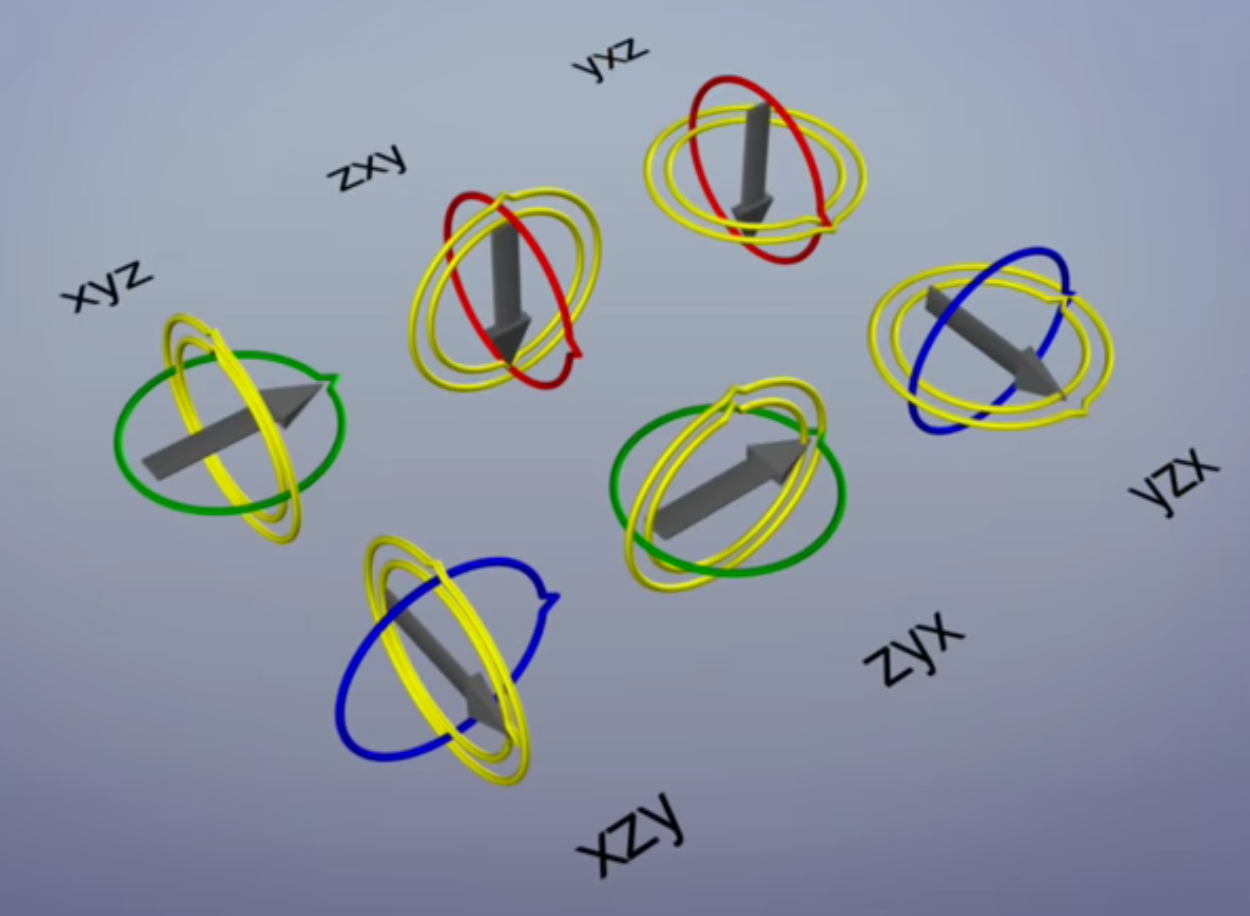
All together there are 6 parenting combinations to choose from. In each case gimbal lock occurs on the parent when the middle axis is rotated too far.
The cause of gimbal lock is the representation of orientation in calculations as three axial rotations based on Euler angles. A potential solution therefore is to represent the orientation in some other way. This could be as a rotation matrix, a quaternion , or a similar orientation representation that treats the orientation as a value rather than three separate and related values. Given such a representation, the user stores the orientation as a value. To quantify angular changes produced by a transformation, the orientation change is expressed as a delta angle/axis rotation. The resulting orientation must be re-normalized to prevent the accumulation of floating-point error in successive transformations. For matrices, re-normalizing the result requires converting the matrix into its nearest orthonormal representation. For quaternions, re-normalization requires performing quaternion normalization.
To avoid gimbal lock, we can use quaternion. Quaternion is a complex system in math.
In mathematics, the quaternion number system extends the complex numbers. Quaternions were first applied to mechanics in three-dimensional space. Hamilton defined a quaternion as the quotient of two directed lines in a three-dimensional space, or, equivalently, as the quotient of two vectors. Multiplication of quaternions is noncommunicative. Quaternions are used in pure mathematics, but also have practical uses in applied mathematics, particularly for calculations involving three-dimensional rotations, such as in three-dimensional computer graphics, computer vision, and crystallographic texture analysis. They can be used alongside other methods of rotation, such as Euler angles and rotation matrices, or as an alternative to them, depending on the application. It can avoid Gimbal Lock.
The detail of an angle’s quaternion is a matrix shown below:
Quaternion matrix to describe the rotation
1 | StartPoint(x1, y1, z1, 1) |
The Euler angle between start point and the end point: θ, can be inversely calculated out through a quaternion for test, and it is equal to 2*arccos(Quaternion.w) when being inverted.
Here is the detailed method to get quaternion in real code:
1 | Vector4 GetQuaternion(const Vector2 & lastPointV2, const Vector2 & curPointV2) |
You can see that the function above includes a function called ArcBallTransform, which is a mathematical way to map the 2D point onto a 3D sphere, thus making it possible to describe the user's interaction from 2D screen to 3D virtual world space. The detail of the arc ball transform goes like the code shown below:
1 | float GetKFactorForArcBall(const float para) |
Changing the location(Translating the objects/models) directly from the screen-side(eg: the user clicked to select an object and moved the mouse from one point on screen to the other just to make the selected object move as the mouse’s track) is also in the same way I have mentioned above, but is much easier than doing rotation via arc ball transform plus quaternion. Only the subtraction of the 2 points is needed without any complicated calculations. However, the selection of the object/model in virtual 3D world space from 2D screen is a little bit hard for most of the fresh-hands for it demands some more bounding-box related algorithms and knowledge basis to achieve this.
Now here is the details of the translation transform matrix, through which we are able to translate an object from one place to another in a 3D world space:
1 | TranslationMatrix = { |
And here is the way to get the translation matrix in C++:
1 | Matrix4f Matrix4f::getTranslateMatrix(const float& x, const float& y, const float& z) |
After the translation, we might need some ways to scale the models/objects in 3D world space so that the things can be in the size we expected. Here is the detail of the scale matrix:
1 | ScaleMatrix = { |
Here are 2 ways to get the scale matrix in C++:
1 | Matrix4f Matrix4f::getScaleMatrix(const float& x, const float& y, const float& z) |
All the transforms in world space from either the user interaction or the preset automation is conducted through matrices. The vertices multiplies the world space matrix, translation matrix, scale matrix as well as rotation matrix, the order of multiplying with the scale matrix, translation matrix and rotation matrix can be various be they should always be on the right side of the multiplication when using the ‘vector • matrix’(vector-on-the-right-side) rule. Otherwise, the transpose of them is needed to carry out the transformations correctly.
The formula goes like this:
1 | ModelInWorldSpaceAfterScaling = ModelInWorldSpace * ScaleMatrix |
1 | ModelInWorldSpaceAfterRotation = ModelInWorldSpace * RotationMatrix |
1 | ModelInWorldSpaceAfterTranslation = ModelInWorldSpace * TranslationMatrix |
1 | ModelInWorldSpaceAfterTransform = ModelInWorldSpace * ScaleMatrix * RotationMatrix * TranslationMatrix |
The second step is to transform the model from the world space into the view space. In order to create a view space, we have to construct a camera first. The main functions of this camera is to shot the models in scene and send the rendering data onto screen so that we can see what’s happening in the virtual 3D world. You can either separate the camera out as a single class or just inject it into the one of the class you think injectable and appropriate.
Before constructing a camera, we should learn the main function that the camera has to do for us while rendering. To make it more specific, the camera can be regarded as our eyes in the virtual 3D world, and in this way you’re going to realize the first thing the camera have to solve: seeing the models. How to see those models in the scene? There should be some rules so that the view is in correct and non-distorted state. Here are some rules we have to consider:
- The up-axis of the camera [In order to view the models/objects correctly];
- The position we are viewing the models from [We have to keep a distance from the models we want to see so that we can see them];
- The target of the camera that is shooting [In oder to specify the shooting position];
These three aspects are crucial for a camera to shoot the models or objects in a 3D space correctly, so we are going to build up a way to describe the way a camera shoots the scene. In computer graphics, we still use a matrix to describe the way, but there are 2 types of rule that the one is in left-hand coordinate while the other is in right-hand coordinate. Just use the one that you will not change in the future. In this book I use the left hand coordinate system in building up my camera matrix, which is called “LookAtMatrix” formally in the project. Let’s just take a look at the details of the view matrix we are going to use:
1 | Matrix4f getLookAtMatrixForLeftHandCoordinate(Vector3 * eyePos, const Vector3 * lookAt, const Vector3 * up, Vector3 & newCameraUpAxis) |
It’s just creating a virtual camera for shooting the virtual 3D world using matrix. Ones all the significant information is stored in the matrices, it will be so easy for us to apply them onto the models in the 3D world be rendered. The result of the matrix we gain via the function above is the origin of our view matrix. So we apply the matrix we gain by using the function above to an empty matrix to store our view matrix. Now you will realize that you can directly regard the view matrix as the ‘camera matrix’ or ‘eye matrix’, any transforms conducted onto the camera shall directly be conducted on the view matrix.
Now that we gained the view matrix singly by configuring the camera we are using in the virtual 3D world, we can transform the vertices from the world space into the view space just by updating the vertices in the world space through: multiplying the vertex positions already in the world space with the view matrix.
1 | ModelInViewSpace = ModelInWorldSpace * ViewMatrix; |
Till now, we have successfully transformed the models from the world space into the view space, next step after this is the transform of the model from the view space into the projection space. In order to make the transform, we have to gain projection matrix first.
There are 2 kinds of projections in our life, the one is orthographic while the other is perspective.
In the orthographic projection, the things we see will be shown in the shape based on its original geometric shape, non-distorted surfaces with all of the lines and points mathematically-ordered. For this reason, we use a cube to project the objects/models in the view space, all the shapes are projected mathematically through a cube.
In the perspective projection, the things we see will be shown in the shape based on its realistic shape we see in our real life. It seems ‘realistic’ just because of the fact that the human eyes see things in perspective view, the shapes of the objects in real life is distorted when it is being projected into our brains from our eyes: mastering the rule that “Everything looks small in the distance and big on the contrary”. For this reason, we use cone to project the objects/models in the view space rather than a cube, all the shapes are projected from a point, also, the furthest objects will disappear and become as a point after the projection.
Since we have noticed the main difference of 2 types of projection, the question lingers: What elements are needed when acquiring the projection matrix?
As we use a geometry to make the projection process(using a cube to make the orthographic projection while using a cone to make the perspective projection), the properties of the geometry selected shall be the attributes we have to consider when making the projection. We store the projection space in a 4x4 matrix as we did for the world space and view space before.
A cube has its width, height and length. When projecting, it’s enough for us to build out an orthographic projection matrix using these 3 attributes. We use its length to represent the distance from the nearest z-position(zNear) to the furthest z-position(zFar). Any objects/models outside this range will not be seen and should be clipped away so that they will not be rendered on screen. We usually set a small number, for example 0.2 as the nearest z-position while a bigger like 500 as the furthest z-position. Conus left can be 0 while the conus right should be the width of the cube, conus bottom can be 0 while the conus top should be the height of the cube. Here is the details of the orthographic matrix:
1 | Matrix4f Matrix4f::getOrthographicMatrix(const float conusLeft, const float conusRight, const float conusBottom, const float conusTop, float zNear, float zFar) |
A cone, however, is different from a cube, and it has not width or height. Apart form using its length to represent the distance from the nearest z-position(zNear) to the furthest z-position(zFar), we use its angle on roof to represent the viewing field, which is formally called: field of view. And there is another element we have to consider when building the perspective matrix, that is: aspect ratio, which is the ratio of the rendering view’s(or the image’s) width to its height, and is expressed with 2 numbers separated by a colon, such as 16:9. Its simple to gain the aspect ratio once we configured the target rendering height and width. In the final project accompanied with this book, I used 720 as window width and 576 as window height, which means the aspect ratio is 720:576. By now, we have all the important information gained from a cone to build out a perspective projection matrix, which represents the perspective projection space itself. Let’s take a look at the details of the perspective matrix below:
1 | Matrix4f Matrix4f::getPerspectiveMatrix(float fovYOZ, float aspectRatio, float zNear, float zFar) |
Then the way to transform the vertices from the view space into the projection space is as easy as what we have done when transforming the vertices form the world space into the view space: multiplying the model information matrix in view space with one of the projection matrix we calculated above. The formula goes like this:
1 | ModelInProjectionSpace = ModelInViewSpace * ProjectionMatrix; |
Notice that we should choose one type of projection at a time so that we can view in relevant projection mode, so the exact formula in a frame goes like this:
When using perspective mode
1 | ModelInPerspectiveProjectionSpace = ModelInViewSpace * PerspectiveProjectionMatrix; |
When using orthographic mode
1 | ModelInOrthographicProjectionSpace = ModelInViewSpace * OrthographicProjectionMatrix; |
Till now we have successfully processed the MVP transform, here is the recitation of the MVP transform in a nut shell:
(matrices are all with type:matrix4f)
(positions are all with type:vector4)
1 | ModelInWorldSpace = ModelVertices[n].position * WorldMatrix; |
1 | ModelInViewSpace = ModelInWorldSpace * ViewMatrix; |
1 | ModelInProjectionSpace = ModelInViewSpace * ProjectionMatrix; |
After we have transformed the vertices into the relevant projection space(perspective or orthographic), we have to make clippings. Clipping is a way to ignore the vertices that need not to be rendered in our visible area. In formula, when a vertex is inside the frustum, its position in X-axis and Y-axis will lay among the range of [-w, w] while its position in Z-axis will be in the range of [0, w]. So we can use this formula to check whether a vertex is inside the frustum. Here is the detail of the way to check whether a vertex is inside the CVV:
1 | bool IsOutsideCVV(const Vector4& v) |
A similar step with clippings is back culling, which is a way to ignore the back side of the model being rendered so that the rendering efficiency may be accelerated. When culling the backside of the model being rendered in virtual 3D world space, the important thing is to figure out its normal. The normal is decided upon the rule of drawing triangle: if you draw a triangle by connecting the vertices clockwise, the back side of the model is pointed to the inner side to the screen, vice versa. We can easily figure out the normal based on the Right-hand Screw Rule, but in programming, we have to know the way to express the Right-hand Screw Rule: we make subtractions twice to take all the three points into consideration as well as pretending to screw from one point to the other, then we calculate the cross product of the first point with the second point(or the second with the third, as is shown using ‘way 2’ below, but the points must be in continuity so as to pretend the screwing correctly). This normalized cross-product result best describes the normal of three points — the triangle. The back side of a primitive is easily figured out in this way. Here is the detail of CVV-Clipping and back-culling in my simple project:
1 |
|
You can see that the points are just prevented from being sent to the rasterization stage when we are culling the back. The points are prevented from going to the next steps when clipping also.
There is a step not mentioned above that we may do before making the projection(inside the MVP, before ‘P’): shading lights. Shading lights is an operation conducted on textures of the models. When shading the light, lots of algorithms is used. In the final project asides this book, I showed the way of computing light and shading the light in Lambert mode. Main formula of Lambert Lighting is :
1 | I = Ia * Ka + Ip * Kd * (N·L) |
1 | I = Ia * Ka + Ip * Kd * cosTheta; |
The details of lighting are shown below:
1 | struct Light |
After the MVP transform and clippings, we know that the models state does not change at all, they are still in 3D state, but we have to see it on a 2D screen, so the screen mapping comes to help us transform the 3D vertices into the 2D screen. Screen mapping is a technic that maps the 3D vertices to the 2D screen. As is the codes shown above in function ‘DrawTriangle’, we simply call it Homogenize: the way to transform the vertices from the projection space into the screen space. Here is the detail of homogenizing a vertex:
1 | void Homogenize(Vector4& result, const Vector4& posInProjectionSpace) |
After such a long process, with the pixels we have just gain, we are entering into the next stage: rasterization stage, where we conduct multiple operations on each pixel so that each of the frame — namely an image, formed of many pixels — rendered on screen is in ideal state.
3. Rasterization Stage
The vertices we gain in screen space during the geometry stage will be used for drawing the final image, formally: single frame, that we are able to see directly.
After the screen mapping, through which we transformed the vertices from projection space to the screen space, some of the processes is still needed to make out a single frame to be rendered, and these processes are conducted in rasterization stage. Actually, it is the rasterization stage that converts vector information (composed of shapes or primitives) into a raster image (composed of pixels) for the purpose of displaying real-time 3D graphics.
During rasterization, each primitive is converted into pixels, while interpolating per-vertex values across each primitive. Rasterization includes clipping vertices to the view frustum, performing a divide by z to provide perspective, mapping primitives to a 2D viewport, and determining how to invoke the pixel shader. While using a pixel shader is optional, the rasterizer stage always performs clipping, a perspective divide to transform the points into homogeneous space, and maps the vertices to the viewport.
The positions[type:Vector4(x,y,z,w)] in each vertices, coming into the rasterizer stage are assumed to be in homogeneous clip-space. In this coordinate space the X axis points right, Y points up and Z points away from camera.
You may disable rasterization by telling the pipeline there is no pixel shader, and disabling depth and stencil testing. While disabled, rasterization-related pipeline counters will not update. There is also a complete description of the rasterization rules. Rasterization rules define how vector data is mapped into raster data. The raster data is snapped to integer locations that are then culled and clipped (to draw the minimum number of pixels), and per-pixel attributes are interpolated (from per-vertex attributes) before being passed to a pixel shader. There are several types of rules, which depend on the type of primitive that is being mapped, as well as whether or not the data uses multi-sampling to reduce aliasing. More related topics is available online and in this book we are just talking about the simple steps to create the usable pixels for rendering.
The vertices are placed in screen space after being clipped in projection space, but not formally, they are still in projection space de facto. Because we only clipped away the vertices outside the projected area, there are still vertices inside the projected area but outside the screen area. Different from the back culling, the vertices outside the screen area/space, which is also called: the view frustum, need to be clipped away not only for the reason that they are useless for rendering, but the consideration of those vertices may explode our frame buffer. Frame buffer is a container that stores all of the pixels going to be rendered on screen. Its volume is screenHeight*screenWidth large, so by now you will realize the importance of clipping of the vertices outside the screen space.
The RHW is the reciprocal of the homogeneous (clip space) w coordinate of a vertex (e.g., 1/w).
Recall that we must expand our 3D vectors to 4D vectors in order to be able to multiply them with 4x4 matrices (which we do because 4x4 matrices allow us to completely encode both rotational, translational, and scaling terms). In doing so we often set (or assume) the expanded fourth (w) component is 1 for model vertices, and the nature of the transforms we use to bring model-space vertices into world or view space doesn’t include any terms that alter the w component.
However, the typical perspective projection transformation often takes the follow general form which, when multiplied with a general view-space vertex vector (x,y,z,1), gives you a vector like (Ax, By, Cz + E, zD) — note that the resulting vertex has a w component that is proportional to the original input’s z component. Also note that the space you’re in after multiplication by this matrix is called clip space, because the nature of the transform has distorted the viewing frustum into a cuboid, the edges of which are much easier to perform clipping against.
After clipping, the graphics pipeline divided by the w component to scale things based on distance to give you the perspective effect. This division cannot be encoded in a matrix transform.
Now, division by w is the same as multiplication by the reciprocal of w, and the reason that you are required to give the reciprocal of the clip space w coordinate is probably a throwback to the time when division was significantly slower than multiplication. When you use pre-transformed vertices, the transformation from model to world to view to clip space is skipped, but the rest of the pipeline (division by w, conversion to window coordinates, and rasterization, obviously) must still happen. Since the projection transform was skipped, there is no basis for the pipeline to determine the w coordinate to divide by, so it asks you for it.
There are some interesting uses for the value, but for the most part people use pre-transformed vertices when doing 2D rendering, and in that case its most useful to set the RHW value to 1, which effectively causes the divide to be a no-op.
The detail of initiating the RHW is shown below:
1 | void VertexRHWInit(Vertex& v) |
There are lots of ways to draw triangles when we have pixels in hand. Each of the way has its pros and cons and we have to choose the correct one to use. BUt in the final project, I provided multiple choices for learning. For example, you can use Point-by-Point Comparison Method to draw a line, it has its costs on performance but also has it advantage on some tiny models which ought to be rendered precisely. And, we can easily put some effects on each of the vertices when drawing the points. Here is the detail of the ‘Point-by-Point Comparison Method’:
1 | void DrawPoint(const Vector4& p, const Colour& color, const Texcoord& tc, const Vector3& normal) |
Here is the detail of the ‘Point-by-Point Comparison Method To Draw A Line’:
1 |
|
You can also choose another ways to draw line. In the final project, I separated the conduction on the pixel in the way below:
1 | void DrawPixel(int x, int y, unsigned int hexColor) |
Besides this way, you can use Bresenhem Way to draw the line, here are the details:
1 | void DrawBresenhemLine(const Vector4 & startPoint, const Vector4 & endPoint) |
The way to draw line in Bresenhem way shown above can even be optimized to the codes below:
1 |
|
Once we are able to draw lines, we are able to draw triangles, too. By calling the method of drawing lines three times can we build out a triangle we want:
1 | // startPoint, endPoint |
Apart from this, we can use Scan-line Way to rasterize triangles on screen, which is the core of our rendering. The detail of the scan-line way is shown below:
1 | void ScanlineFill(const Vertex & leftPoint, const Vertex & rightPoint, const int yIndex, const Colour** texture) |
You can see that we conduct Bilinear Interpolcation in rasterization stage, its a way of avoiding the edges of the texture mapped on the models/pbjects. The details of ‘Bilinear Interpolcation’ is shown below:
1 | Colour BilinearInterp(Colour** textureColorData, const int textureWidth, const int textureHeight, const float u, const float v) |
When rasterizing, notice that the lerping is also needed in screen space for acquiring a correct pixel position on screen. More details of Lerping and resterizing triangles are shown below:
1 |
|
The final process of the rasterization stage is kind of like image processing, its main difference with the image processing is that the rasterization stage process vertices gain in geomotry stage, which means that the pixels are created and converted manually by the real vertices, while the image processing is to process an image from an pure pixel container: image itself. But there is no doubt that many conductions of image processing can be integrated from rasterization stage.
© Alexander Ezharjan
31st, March, 2022